Stop Paying for AI Tokens: How to Build Zero-Cost Sovereign Apps with Next.js 15 & WebGPU
Beyond the Cloud API Dependency: Why Modern Developers are Shifting to Sovereign, Local-First AI Stacks
The tech landscape in 2026 is experiencing a quiet execution of independence. For the past few years, building an AI-powered feature followed a predictable, almost lazy blueprint: install an SDK, grab an API key from a centralized cloud provider, hit an endpoint, and pray the pricing tier or latency doesn’t break your business model.
It worked as a proof of concept. But as applications scale and user expectations mature, developers are hitting a wall built of unpredictable API costs, compliance nightmares, and the structural fragility of relying entirely on external servers.
If your entire business logic depends on a third-party model remaining cheap, fast, and unchanged, you don't own a software product—you own a frontend wrapper. This reality is driving a massive architectural shift toward Sovereign AI and Local-First Development. Developers are actively moving intelligence directly to the edge and the user's browser, building apps that run locally, cost nothing to scale, and remain functional even when disconnected from the internet.
The Hidden Costs of the Centralized AI Paradigm
When we first started injecting intelligent features into web platforms, cloud APIs felt like magic. However, production environments eventually reveal the structural cracks of this dependency:
The Scale Tax: Centralized AI services charge you per token. If your traffic spikes, your API bill scales linearly. For a high-traffic system or a dynamic multi-tenant setup, this financial bottleneck quickly destroys margins.
Latency vs. User Experience: round-trips to data centers thousands of miles away introduce a perceptible lag. When building interactive user interfaces, every millisecond counts toward retention.
The Black-Box Vulnerability: Cloud providers update, deprecate, or alter their underlying models without warning. A prompt that yields pristine JSON output today might return broken strings tomorrow, forcing teams into endless debugging cycles.
To bypass these limitations, modern web engineering teams are changing their strategy. Instead of paying a premium to query someone else's infrastructure, they are building custom data pipelines and optimizing local resources to handle the heavy lifting.
The Pillars of the New Local-First Web Stack
Building a zero-cost, high-performance AI system requires rethinking how data flows between the server and the browser. The modern local-first approach relies on a powerful triad: a robust full-stack meta-framework, a lightning-fast database layer, and client-side hardware acceleration.
+---------------------------------------------------------+
| Modern Full-Stack UI |
| (Next.js 15) |
+---------------------------+-----------------------------+
|
+---------------+---------------+
| |
+-----------v-----------+ +-----------v-----------+
| Client-Side Edge | | Server Infrastructure |
| (WebGPU / Local LLMs) | | (PostgreSQL + Prisma) |
+-----------------------+ +-----------------------+
1. High-Performance Orchestration (Next.js 15)
To build an app that balances local execution with secure server-side operations, you need a framework that doesn't force a strict choice between client and server. Next.js 15, with its deep integration of Server Components and Server Actions, handles this orchestration effortlessly.
Instead of traditional, bloated API endpoints that require manual fetching configurations, you can execute database mutations, enforce role-based access control, and handle complex streaming workflows directly within your component tree. This architecture allows developers to decide precisely which tasks happen safely on the server and which operations can be offloaded to the user's browser.
2. Predictable, Optimized Data Layers
Local-first apps still require an organized, high-performance database backend to store user preferences, manage authentication states, or handle multi-tenant routing. Using a robust database like PostgreSQL combined with an elegant ORM like Prisma ensures that your structured data stays perfectly synchronized.
When you combine a highly responsive data fetching strategy with advanced caching, you get the absolute best of both worlds: dynamic, data-driven features operating at near-instant speeds without hitting massive server performance bottlenecks.
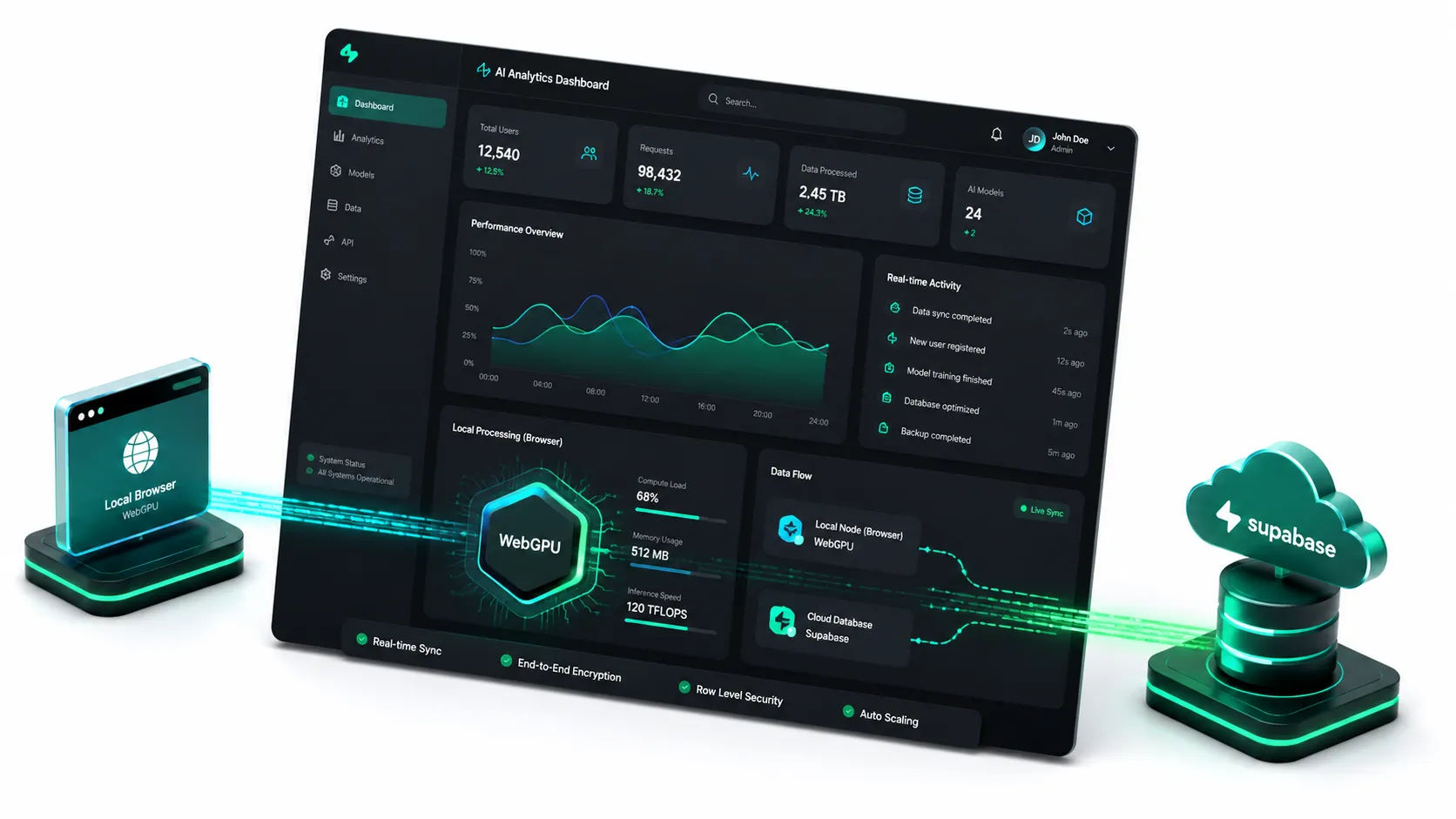
3. WebGPU and Client-Side Intelligence
The true game-changer in recent months is WebGPU. For years, running an AI model meant hosting an enormous, power-hungry Python environment on a specialized cloud GPU instance. Today, modern browsers can access the user’s local graphics hardware directly through WebGPU.
This means you can download compact, highly optimized LLMs (like modified variants of Llama, Phi, or Gemma) directly into the user's browser cache. The processing happens locally on the user's device. The cost to the developer? Absolutely zero.
Step-by-Step Architecture: Combining Server Actions with Client Intelligence
Let's look at how a modern, self-hosted system balances server-side data management with a sovereign client-side architecture. We will structure an approach where the server handles data persistence with Prisma, while the client coordinates the local execution context.
The Database Structure (schema.prisma)
First, we establish a clean database schema to manage user configurations and locally generated logs without over-complicating the underlying infrastructure.
Code snippet
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model UserWorkspace {
id String @id @default(uuid())
name String
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
configs Config[]
logs LocalLog[]
}
model Config {
id String @id @default(uuid())
key String
value String
workspaceId String
workspace UserWorkspace @relation(fields: [workspaceId], references: [id], onDelete: Cascade)
}
model LocalLog {
id String @id @default(uuid())
action String
tokensUsed Int @default(0) // Tracks zero-cost local tokens
workspaceId String
workspace UserWorkspace @relation(fields: [workspaceId], references: [id], onDelete: Cascade)
createdAt DateTime @default(now())
}
The Server Action for State Persistence
With the schema in place, we use a Next.js Server Action to update the workspace metrics and sync state without exposing heavy API surfaces or setting up complex state management libraries.
TypeScript
"use server";
import { PrismaClient } from "@prisma/client";
import { revalidatePath } from "next/cache";
const prisma = new PrismaClient();
interface SyncLogInput {
workspaceId: string;
action: string;
tokens: number;
}
export async function recordLocalExecution({ workspaceId, action, tokens }: SyncLogInput) {
try {
if (!workspaceId) {
throw new Error("Invalid workspace reference encountered.");
}
// Save execution metadata securely on the server
const logEntry = await prisma.localLog.create({
data: {
workspaceId,
action,
tokensUsed: tokens,
},
});
// Instantly refresh the UI cache on the server side
revalidatePath(`/workspace/${workspaceId}`);
return { success: true, logId: logEntry.id };
} catch (error) {
console.error("Failed to commit execution log:", error);
return { success: false, error: "Database synchronization failure." };
}
}
The Client Component Orchestrator
On the frontend, we build a component that checks for WebGPU support, executes the inference locally on the user’s hardware, and fires the Server Action to sync the metadata back to our PostgreSQL database.
TypeScript
"use client";
import { useState, startTransition } from "react";
import { recordLocalExecution } from "@/actions/execution";
interface WorkspaceProps {
workspaceId: string;
}
export default function AutonomousWorkspace({ workspaceId }: WorkspaceProps) {
const [status, setStatus] = useState<string>("Ready for local execution");
const [processing, setProcessing] = useState<boolean>(false);
async function handleLocalInference() {
if (!("gpu" in navigator)) {
setStatus("WebGPU is not supported on this browser device. Falling back.");
return;
}
setProcessing(true);
setStatus("Accessing local GPU pipeline...");
try {
// Simulation of a local LLM execution via WebGPU pipeline
await new Promise((resolve) => setTimeout(resolve, 1200));
const simulatedTokensProcessed = 142;
setStatus(`Execution complete. Processed ${simulatedTokensProcessed} local tokens.`);
// Sync data back to server flawlessly using Server Actions
startTransition(async () => {
const result = await recordLocalExecution({
workspaceId,
action: "Local UI Model Optimization Run",
tokens: simulatedTokensProcessed,
});
if (result.success) {
setStatus((prev) => `${prev} Server updated successfully.`);
}
});
} catch (err) {
setStatus("An unexpected error occurred during local model initialization.");
} finally {
setProcessing(false);
}
}
return (
<div className="p-6 rounded-xl border border-zinc-200 bg-white shadow-sm">
<h3 className="text-lg font-semibold text-zinc-900">Sovereign Processing Unit</h3>
<p className="mt-2 text-sm text-zinc-600">Status: {status}</p>
<button
onClick={handleLocalInference}
disabled={processing}
className="mt-4 px-4 py-2 text-sm font-medium text-white bg-zinc-900 rounded-md hover:bg-zinc-800 disabled:opacity-50 transition-colors"
>
{processing ? "Processing on Device..." : "Run On-Device Inference"}
</button>
</div>
);
}
Maximizing the Experience: Performance and Core Web Vitals
Shifting your application's architecture to a hybrid local/server structure won't matter if your platform takes five seconds to load. Performance optimization is a core component of building modern web applications.
When sending large web worker assets or local model configurations down to the client, developers must protect their Core Web Vitals. If a user experiences visual shifts or delayed interactive capabilities, they will bounce long before your local AI code finishes compiling.
To maintain a flawless user experience, it's essential to follow best practices for asset delivery. For instance, you should optimize image delivery using modern formats like WebP or AVIF instead of legacy formats, which heavily protects your Largest Contentful Paint (LCP) scores. Furthermore, heavy JavaScript bundles required for model coordination should be loaded lazily using dynamic inputs, keeping your initial bundle footprint compact, readable, and highly efficient.
Practical Resources for the Modern Web Ecosystem
Transitioning away from heavy cloud dependencies requires utilizing clean tools designed to solve specific challenges. If you are actively building inside this ecosystem, consider incorporating specialized utilities to accelerate your deployment timeline:
Integrated Technical Utilities
Structured UI Assembly: When scaling specialized platforms or content spaces, skip the boilerplate and leverage specialized design workflows. Check out our comprehensive guide on building an optimized hero image and featured posts section in Nextjs with prisma and tailwind css to structure your main dash.
Custom Tooling Architectures: If you are deploying native client utilities, exploring standalone tools like a clean image compressor or an intuitive image resizer provides excellent inspiration for designing zero-latency browser pipelines.
File Management At Scale: For high-fidelity document generation or building structured client portfolios, review our technical breakdown detailing the ultimate guide to professional pdf generation and 600 dpi conversion to ensure perfect rendering across standard layouts.
The Path Forward: Owning Your Digital Capital
The transition toward sovereign web apps isn't a temporary trend; it's a necessary response to the commercialization of data pipelines. By moving structural logic to local execution nodes, optimizing modern database queries, and utilizing frameworks like Next.js 15 to blend server reliability with client capability, you create resilient systems.
Stop building apps that crumble when an external API changes its pricing matrix. Invest the time into understanding local-first state persistence, harness the computing power already sitting in your users' hardware, and build products designed to last.
Key Takeaways for Production Engineering
Focus Area | Core Strategy | Primary Benefit |
Model Hosting | Switch from Cloud API calls to on-device WebGPU execution | Completely eliminates ongoing token billing matrices |
State Sync | Utilize Next.js 15 Server Actions directly inside components | Removes API routing overhead and handles revalidation instantly |
Database Sync | Maintain decoupled tracking using a PostgreSQL + Prisma layer | Delivers scalable, multi-tenant logging with clean data integrity |